


No dia a dia da cobertura de assuntos ligados à tecnologia, é comum misturarmos os termos Inteligência Artificial (ou AI), Aprendizado de Máquina e Aprendizado Profundo como se fosse uma única coisa. Entretanto, na medida em que ocorrem avançados cada vez maiores nesse ramo, é essencial delimitarmos exatamente o que cada um significa e representa na indústria.
Em termos bem abrangentes, AI implica em fazer um computador imitar o comportamento humano de alguma forma. Esse é o termo mais genérico e não é errado empregá-lo para todas as situações.
Desta forma, dentro desse universo mais genérico, o Aprendizado de Máquina (ou Machine Learning, para utilizarmos o termo globalizado) funciona como um subconjunto da AI. Ele engloba um conjunto de técnicas que permite que computadores aprendam padrões a partir de dados inseridos e entreguem resultados inteligentes a partir disso.
Por último, temos Aprendizado Profundo (ou Deep Learning), que faz parte do processo de Aprendizado de Máquina, mas é um subconjunto de técnicas que envolvem redes neurais mais complexas e permitem resolver problemas mais sofisticados a partir de dados inseridos.
A Oracle elaborou um diagrama bastante explicativo sobre como esses termos se relacionam:
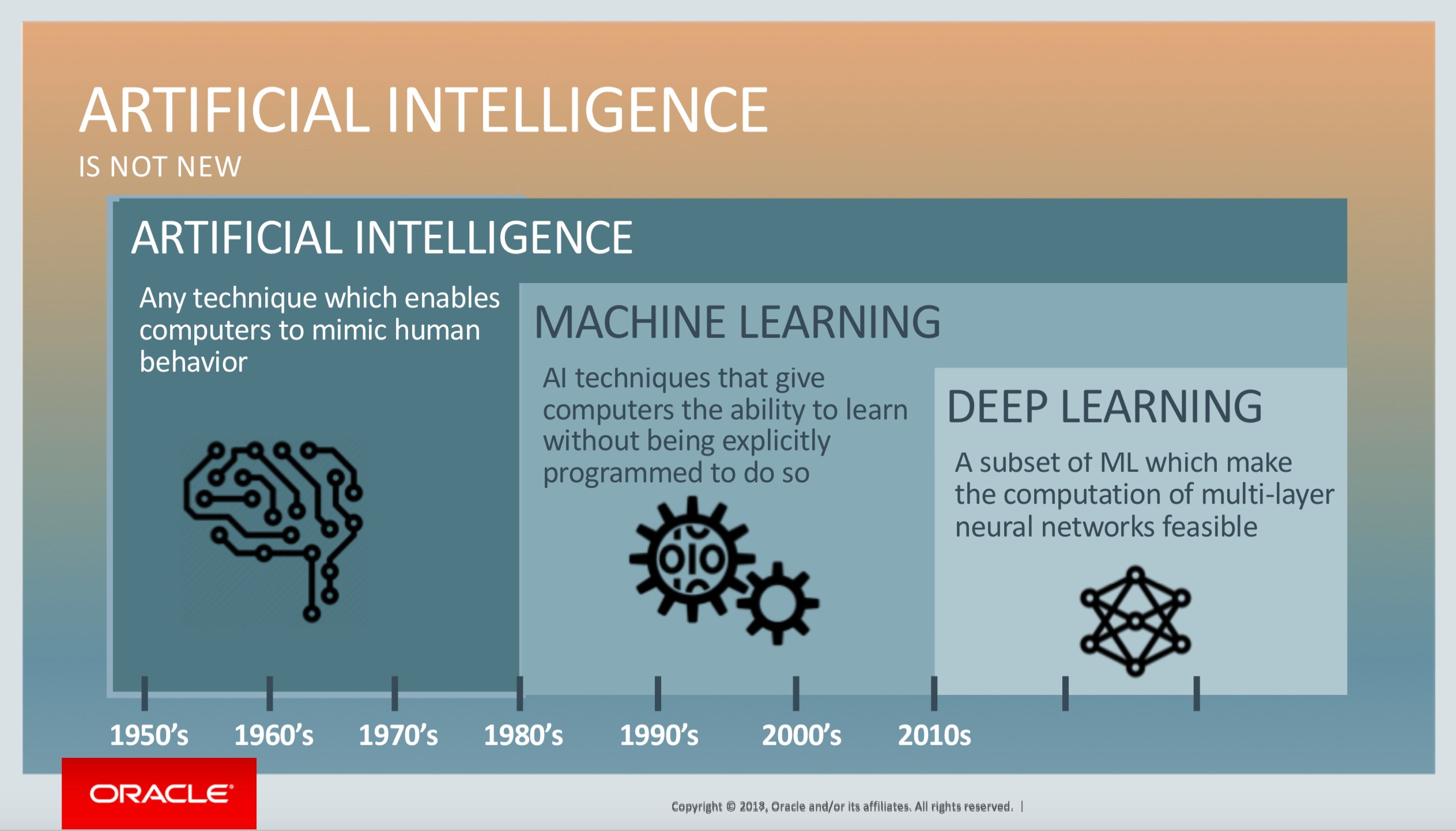
Resumidas as definições, podemos agora analisar mais detalhadamente cada uma das três.
O que é Inteligência Artificial

Por ora, e pelas décadas vindouras, deixe de lado suas visões pré-concebidas de HAL 9000, Skynet ou Matrix. Ainda que o termo Inteligência Artificial tenha sido criado em 1956, por John McCarthy, ele não envolve consciências similares a nossa, tomando decisões sofisticadas ou disputando um lugar de igualdade, mas o conceito de máquinas realizando tarefas que anteriormente eram associadas à inteligência humana.
Então, embora a ficção-científica tenha se prendido na visão de Inteligências Artificiais do tipo geral, capazes de lidar com um amplo espectro de raciocínio, o que temos na prática são as chamadas Inteligências Artificiais estreitas, que exibem apenas uma faceta da inteligência humana e são focadas em funções pré-determinadas. Desta forma, temos sistemas capazes de compreender linguagens, reconhecer objetos e sons, inferir conclusões a partir de dados, aplicar a regra de jogos para obter vitórias etc. Desta forma, uma Inteligência Artificial pode vencer todos os campeões mundiais de Go, mas é incapaz de distinguir um gato de um automóvel.
As primeiras Inteligências Artificiais eram projetadas a partir de um conjunto de regras. Um programa de computador, desta forma, pode ser interpretado como uma “Inteligência Artificial”, seguindo uma sequência de condições e aplicando o resultado para o qual foi projetado. Quanto mais complexo o conjunto de regras, mais poderoso o resultado e mais próximo da “inteligência” humana. Os primeiros adversários de jogos eletrônicos ou mesmo o lendário Deep Blue da IBM funcionavam a partir desa abordagem para solução de problemas.
Existem muitas técnicas diferentes para se obter resultados que se assemelham ao raciocínio humano, entretanto, quanto mais complexos se mostravam os problemas, mais complexas precisavam se tornar as técnicas para abordá-los.A partir dos anos 80, uma delas emergiu sobre as demais: o chamado Aprendizado de Máquina.
O que é Aprendizado de Máquina ou Machine Learning
Apesar do entusiasmo inicial com as possibilidades da Inteligência Artificial, os pesquisadores logo perceberam as limitações das técnicas adotadas até então. Determinados problemas e cenários eram complexos demais para serem trabalhados com algoritmos codificados à mão ou sistemas baseados em regras. Afinal, como se cria uma árvore de decisões para tarefas como reconhecimento de imagem ou significado de um texto? Algo com milhares de linhas de código?
Era fundamental então desenvolver um processo que não buscasse imitar o comportamento humano, mas imitar aquilo que gera o comportamento humano. Era necessário replicar o próprio processo de aprendizado.
Em 1959, Arthur Samuel já apresentava a solução para esse dilema e definia o Aprendizado de Máquina como “a habilidade de aprender sem ser explicitamente programado”. Desta forma, se treina um algoritmo de forma que ele aprenda padrões a partir de vastas quantidades de dados, de forma que o próprio algoritmo se ajuste e se aperfeiçoe de acordo com o volume de informações recebidas.
Esse procedimento pode ser bem exemplificado através do reconhecimento de imagens. Um computador, um sistema, não possui um olho no sentido tradicional, ele trabalha com imagens em formato digital, que nada mais são que um punhado de pixels de cores diferentes. Para que a Inteligência Artificial entenda o que aquela imagem significa, ela precisa ser ensinada.
A partir daí, os pesquisadores coletam centenas de milhares ou mesmo milhões de imagens que já foram marcadas previamente por um humano real. Com essa classificação, o algoritmo irá tentar montar um modelo baseado nas semelhanças e diferenças das marcações realizadas por uma inteligência humana. Quanto maior o volume de dados e mais preciso o algoritmo desenvolvido, será uma obtida uma eficácia maior no reconhecimento: a máquina terá “aprendido” a identificar aquela imagem.
Esse é o processo envolvido em carros autônomos, que identificam placas, ruas e outros veículos dessa forma. Não por acaso, mecanismos de CAPTCHA utilizam mão de obra gratuita de milhares de usuários todos os dias para classificar essas imagens e ajudar a construir o banco de dados necessário para o Aprendizado de Máquina.
Quando a entrada de dados é adulterada ou o algoritmo é mal fabricado, temos resultados catastróficos, como a infame Inteligência Artificial conversacional da Microsoft. Quase quatro anos depois, o projeto segue fechado para o público.
Novamente, apesar de todos os avanços na área, os pesquisadores esbarraram novamente em limitações para a evolução da Inteligência Artificial com Aprendizado de Máquina. Tarefas simples que uma criança seria capaz de executar, como reconhecimento de escrita à mão ou mesmo narrativas orais, ainda são complexas demais para serem decifradas por máquinas.
Novas e melhores técnicas foram sendo desenvolvidos para complementar ou tentar outro ângulo no campo: decision tree learning, programação em lógica indutiva, clustering, Reinforcement Learning, redes bayesianas e outras.
Os pesquisadores entenderam que não bastava reproduzir como humanos aprendem, mas precisavam ir mais fundo: tentar reproduzir o próprio funcionamento do cérebro humano. Surgiam então as chamadas redes neurais e o Aprendizado Profundo.
O que é Aprendizado Profundo ou Deep Learning

A ideia de reproduzir artificialmente o complexo mecanismo do cérebro é algo que vem sendo sonhado há décadas. Redes neurais nada mais são que uma tentativa, ainda em seus primórdios, de recriar uma estrutura de neurônios conectados por sinapses. Essa abordagem levou ao chamado Aprendizado Profundo e à solução de problemas progressivamente mais complexos no campo da Inteligência Artificial, baseados em Artificial Neural Networks (ANN).
Nessas redes, existem “neurônios” que se inter-relacionam em camadas e conexões com outros “neurônios” na mesma rede, adicionando a “profundidade” ao processo, em oposição à camada única empregada no Aprendizado de Máquina tradicional.
Basicamente, os avanços mais surpreendentes vistos recentemente nessa indústria vieram desse ramo. E, apesar de tudo, estamos falando aqui de redes neurais que envolvem apenas centenas ou milhares de “neurônios”, uma pálida fração dos 86 bilhões de neurônios existentes em um cérebro humano, não apenas mais numerosos mas também melhor conectados com um nível de complexidade que está longe de ser compreendido, quem dirá simulado.
Décadas depois de seu nascimento como campo teórico, apenas agora coletamos os primeiros frutos significativos da Inteligência Artificial. A tecnologia ainda tem um longo e promissor caminho pela frente e a divulgação de seus avanços e meandros é fundamental para incentivar seu desenvolvimento e aceitação no dia a dia.

