Ninguém gosta de CAPTCHAs. Se alguém do seu lado falar que gosta de CAPTCHAs, provavelmente ele é um robô, então largue tudo que está fazendo e corra, sem olhar para trás. O Apocalipse das Máquinas começou e os CAPTCHAs agora são inúteis.
No mundo cor de rosa da web, todo o tráfego é composto por felizes consumidores, navegando de aba em aba, comprando coisas, deixando suas impressões, sendo catalogados, recebendo publicidade de acordo com seus hábitos e impressões, para que eles comprem mais coisas.
Só que, na dura realidade da internet, mais da metade do tráfego é realizado automaticamente, por máquinas. Não estou inventando esses dados. É a mais pura verdade. Inclusive há uma grande possibilidade de que “você” sequer esteja lendo essas linhas, de que você seja um robô também. E a única coisa que garante para você que EU não sou um robô é porque a tecnologia para escrever artigos engraçados não existe. Ainda. Mas vamos chegar lá.

E o que isso tem a ver com CAPTCHAs? Eles são nossa última linha de defesa contra a automação total da navegação pela web. E essa linha de defesa pode estar ruindo.
Curso Rápido Sobre CAPTCHAs (para Humanos)
Completely Automated Public Turing test to tell Computers and Humans Apart, também conhecidos como CAPTCHA, significa “Teste Público de Turing Completamente Automático para Separar Humanos de Computadores”. É um nome horrível, o que prova que nós seres humanos, principalmente nós de TI, somos péssimos para inventar nomes. O pessoal de marketing é muito melhor nisso, mas, bem, eles não são humanos.
(brincadeira, pessoal, amamos vocês)
Na prática, CAPTCHA então é um método automático (ah, a ironia) para identificar uma atividade gerada por um ser humano e diferenciar daquela gerada por um computador ou bot. É o que impede, por exemplo, que um script fique tentando todas as letras do alfabeto e os números em diversas ordens, por dias a fio, até descobrir sua senha de Gmail. Você não vai querer que seus nudes parem na mão de qualquer robô safado por aí. Muitos sistemas de login (os melhores, para sermos honestos) exigem que você passe por um teste de CAPTCHA para autenticar sua sessão.
No começo dos tempos, ou seja, vinte anos atrás, bastava uma confusão de letras em uma imagem para “desafiar” os bots. Hoje em dia parece incrível, mas um punhado de linhas tortas já bastavam para travar o acesso. Você poderia pedir para o “usuário” digitar um texto qualquer em um campo e o bot já pararia sem saber o que fazer. Bons tempos, tempos ingênuos.

Entretanto, é claro que os criadores de scripts passaram a introduzir reconhecimento de texto em suas rotinas. Suas máquinas aprendiam na medida em que seus mestres ensinavam. E as palavras começavam a ficar difíceis demais para nós humanos.
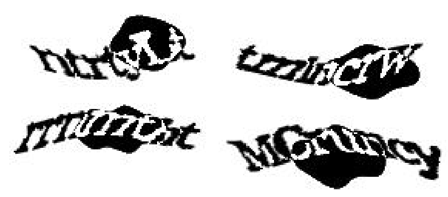
O Google ferrou com tudo, mas foi por uma boa causa
Em 2014, o próprio Google apontou que seus algoritmos de reconhecimento de texto eram capazes de obter uma margem de acerto de 99.8% contra pífios 33% obtidos por humanos. Aquelas letrinhas tortas eram chatas mesmo e não estavam mais segurando as máquinas.
Sem qualquer noção das consequências, o Google teve uma brilhante ideia. Só que não. Mas enfim, a ideia era selecionar fragmentos de textos do Google Books ou fotos de estrada, de ruas, de sinais de trânsito, de animais e usar isso como CAPTCHA. Humanos conseguiriam reconhecer o texto, independente da fonte usada, conseguiriam distinguir a diferença entre um felino doméstico e, digamos, uma hortaliça. Bem, se você não sabe a diferença, cuidado nas refeições.

A malandragem do Google era utilizar sua plataforma de CAPTCHA e os resultados obtidos para fazer ajustes finos em seus próprios algoritmos de reconhecimento. Todo mundo que estava passando nos testes estava ajudando o Google Books a fazer reconhecimento de caracteres. Todo mundo que estava apontando fachadas de loja estava dando uma força para o Google Street View. Todo mundo que estava gastando segundos para identificar placas estava ajudando a melhorar os sistemas dos carros autônomos do Google. E gatos? Bem, todo mundo adora gatos. E isso também ajudaria nos algoritmos do Google Images.
É tudo muito bonito no papel, mas o Google estava, na verdade, ensinando as máquinas a serem melhores em enganar outras máquinas. Dois anos depois, em 2016, o pesquisador Jason Polakis, da University of Illinois, usou o feitiço contra o feiticeiro. Polakis provou que era possível usar os algoritmos de reconhecimento de imagens do Google para decifrar CAPTCHAs de imagem e usar os algoritmos de reconhecimento de voz do Google para decifrar CAPTCHAs de áudio. Sensacional a ideia de melhorar o aprendizado das máquinas, não?
Então, por culpa do Google, texto, imagem e áudio podiam ser decifrados por máquinas. Para ser absolutamente honesto, a culpa nem é do Google. Se eles não tivessem pensado nisso, alguém em algum lugar faria a mesma coisa, fosse Microsoft, Apple, Samsung ou algum hacker de porão.
NoCaptcha ReCaptcha…
… é mais um daqueles nomes que provam que o pessoal de TI precisa de ajuda. Mas a proposta do NoCaptcha ReCaptcha é abolir o CAPTCHA. Ao invés de interpelar o usuário com desafios, o comportamento de navegação do usuário estaria sendo analisado constantemente.
Você já viu isso em ação: é um botão escrito “eu sou humano”, você clica e o site deixa você passar! “Como pode isso?! Quem garante que eu não sou mesmo um robô?”, você já deve ter se perguntado. Parabéns por ter perguntado: você é humano. Um robô não teria dúvidas.

Então, respondemos: a página está avaliando seu comportamento antes, durante e depois de clicar no botão. Um robô poderia ser programado para clicar diretamente, sem erros, matematicamente preciso. Um humano demora um tempinho pra ler, o mouse passeia, a mão dá tremidas imperceptíveis, ele faz gestos de impaciência com o mouse e diversos outros fatores “humanos” que o Google não conta.
Vitória? Por enquanto, tudo indica que sim. Isso não bloqueia fazendas de cliques, onde seres humanos de verdade se autenticam em sites em troca de centavos e realizam tarefas típicas de bots, mas, ei, não se pode ganhar todas, certo?
O Futuro dos CAPTCHAs
O dilema do Google pode se repetir: ao ensinar algoritmos a reconhecerem comportamentos humanos, estaríamos também aprendendo a simular esses mesmos comportamentos, da mesma forma que aconteceu com o aprendizado de máquina para reconhecimento de texto, foto e áudio.
A opinião dos especialistas é que o sistema de CAPTCHA se torne ainda mais invisível e que toda a experiência da web seja auditada continuamente para identificar padrões típicos de seres humanos. Ou, melhor dizendo, a falta de um padrão mecânico. Ao invés de verificar se o usuário no momento em que ele tenta se autenticar em um site ou serviço, essa autenticação aconteceria o tempo todo e, consequentemente, seria muito mais difícil de simular.

Desta forma, os criadores de bot precisariam simular toda uma vida de atividades na web para seus scripts, para ludibriar outros bots capazes de detecção. É uma guerra. Quem já viu um perfil falso no Twitter ou outra rede social, com sua simulação de atividade real, entende que isso já está acontecendo agora mesmo, embora ainda de uma forma rudimentar.
Para complicar a situação, para implementar esse nível de “CAPTCHA”, seria necessária uma multitude de rastreadores compartilhados, cookies e outros brinquedinhos que causam arrepio na sua privacidade. Seria esse o preço a se pagar para evitar que as máquinas invadam a web de vez? Seria preciso escolher: uma distopia de monitoramento constante ou uma distopia onde grandes interesses capazes de pagar legiões de bots manipulariam resultados, análises e logins?